Alan Devkota

Research experience in Transformer Neural Networks and AI, Design of Physical-layer Transmission Technologies for Next-generation Wireless Systems (Massive-MIMO, IRS and Relay Networks, Simultaneous Wireless Information and Power Transfer)
Previous Page: Back to Home | My Resume: Alan
Projects
All my Project can also be found in my Github Repositories Link to my Github Repositories
Performance Analysis of IRS-Assisted Relay Systems
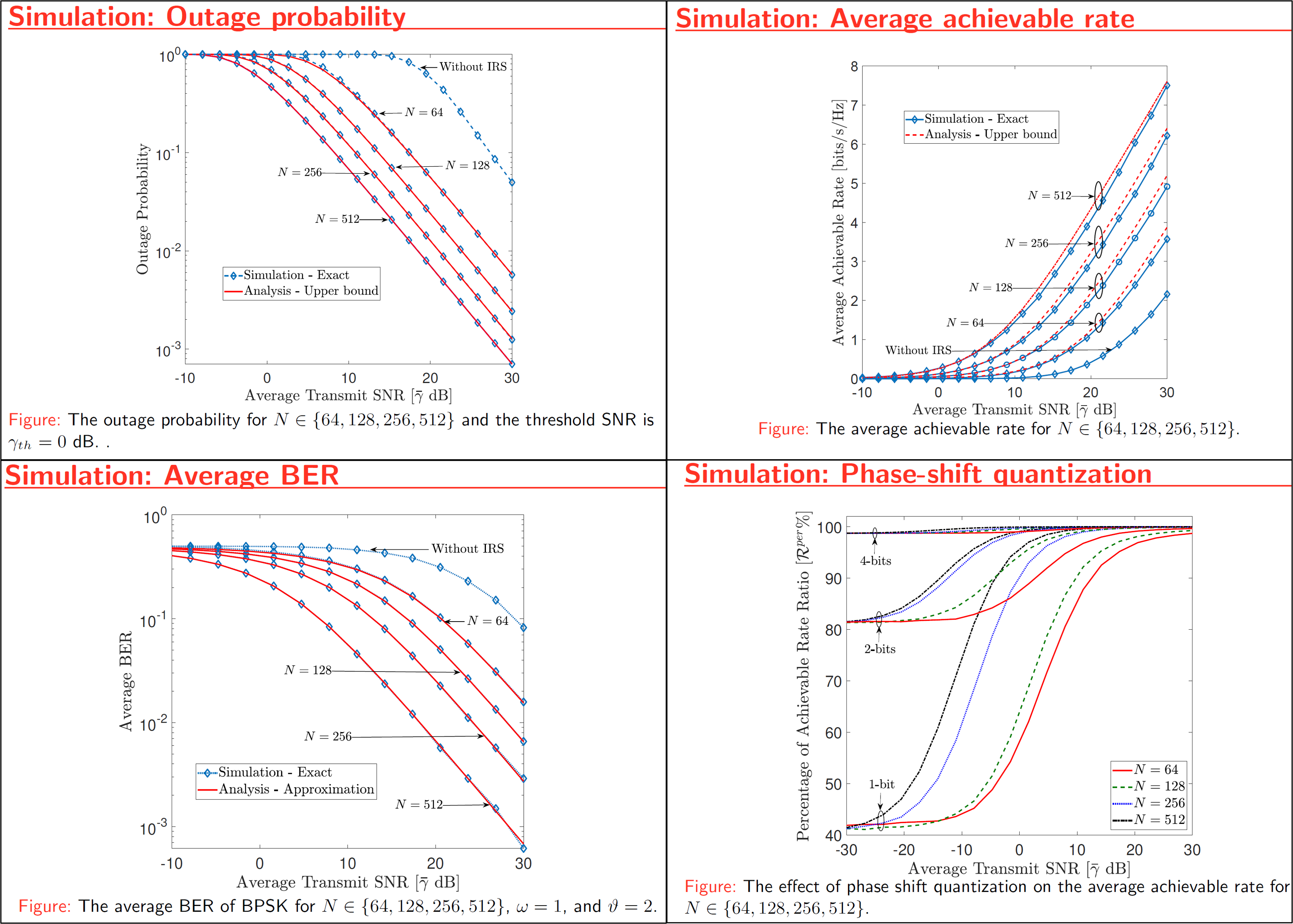
This project investigates the performance of intelligence reflective surface (IRS)-assisted relay systems. To this end, we quantify the optimal signal-to-noise ratio (SNR) attained by smartly controlling the phase-shifts of impinging electromagnetic waves upon an IRS. Thereby, a tightly approximated cumulative distribution function is derived to probabilistically characterize this optimal SNR. Then, we derive tight approximations/ bounds for the achievable rate, outage probability, and average symbol error rate. Monte-Carlo simulations are used to validate our performance analysis. We present numerical results to reveal that the IRS-assisted relay system can boost the performance of end-to-end wireless transmissions.
Please view my project in Github for MATLAB codes, Presentation Slides, Figures and Results (Click here to open: Github-Repo-link )
Please see my presentation slides here (Click here to open slides: presentation-slides )
Please see my GLOBECOM 2021 presentation video here (Click here to open the conference video: Alan_Devkota_presentation )
Energy Harvesting in RIS-Assisted Relay Networks
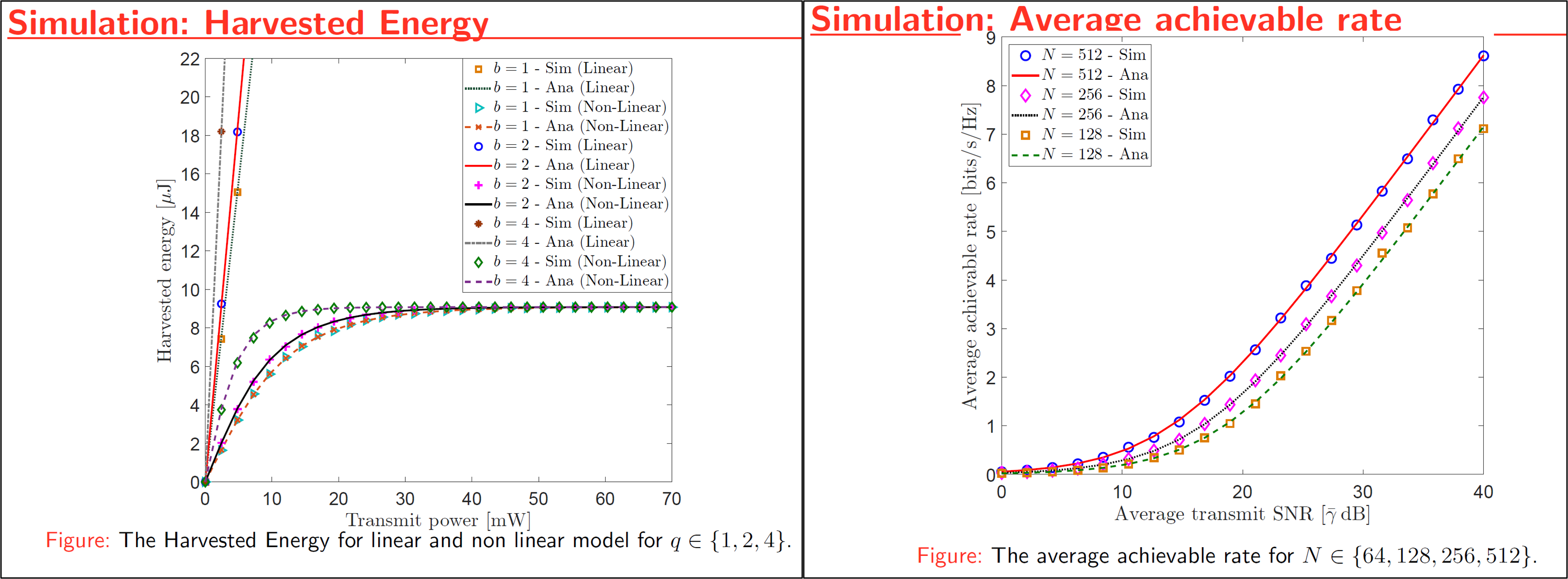
As a part of my Master’s thesis the performance of simultaneous wireless information and power transfer (SWIPT) is explored for a Reflecting Reconfigurable Intelligent Surface (RIS)-assisted relay system. Because radio-frequency (RF) signals can convey both information and energy simultaneously, there has been much research interest in designing novel technologies for simultaneous wireless information and power transmission (SWIPT) and energy harvesting (EH). First, an RIS-assisted relay system model is proposed to improve the wireless system performance. By characterizing the optimal signal-to-noise ratio (SNR) attained through intelligent phase-shift controlling, the performance of the RIS-assisted relay system is investigated. Towards this end, tight bounds for the average achievable rate and optimal harvested energy are derived in closed-form for a hybrid SWIPT protocolThen, the performance of simultaneous wireless information and power transfer (SWIPT) is explored for the proposed RIS-assisted relay system. Also, the performance of linear EH models and non-linear EH models are compared via analytical and Monte-Carlo simulation results.
Please view my project in Github for MATLAB codes, Presentation Slides, Figures and Results (Click here to open: Github-Repo-link )
Please see my presentation slides here (Click here to open: Alan_Devkota_presentation )
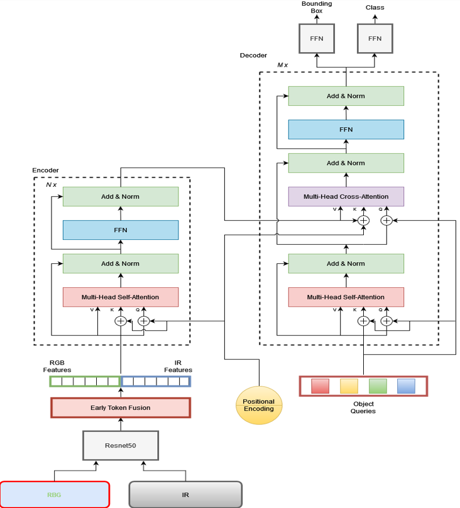
Multispectral Object Detection using DETR with Early Fusion of Tokens
A topic we cover in this experimentation is using Detection Transformers (DETR) as a means to conduct Multispectral Object Detection. Here we are using ResNet50 to extract features of both RGB and thermal images and then provide early token fusion by concatenating the extracted features from ResNe50 together and computing attention between the tokens of RGB and IR modalities to get learned feature representations.
Our methodology leverages a dual-modality approach using both RGB and Infrared (IR) images to enhance the robustness and accuracy of object detection. Both modalities assume a distinct role which provides a more holistic understanding of the object(s) of focus. The process is subdivided into three main stages, a backbone of CNN to extract the features from both RGB and Thermal IR images, a transformer architecture that consists of an encoder and decoder to learn the contextual information between the embedded features, and two classifier units to predict class and bounding box for each object detected inside an image. Here we are using ResNet50 to extract features of both RGB and thermal images and then provide early token fusion by concatenating the extracted features from ResNe50 together and computing attention between the tokens of RGB and IR modalities to get learned feature representations. Our approach relies on transformer architectures, which are powerful tools that are typically used for language tasks. The versatility of these transformers allows us to extend behavior and comprehension of the larger-scale environment.
Architecture
Object Detection Results

Evaluation Results
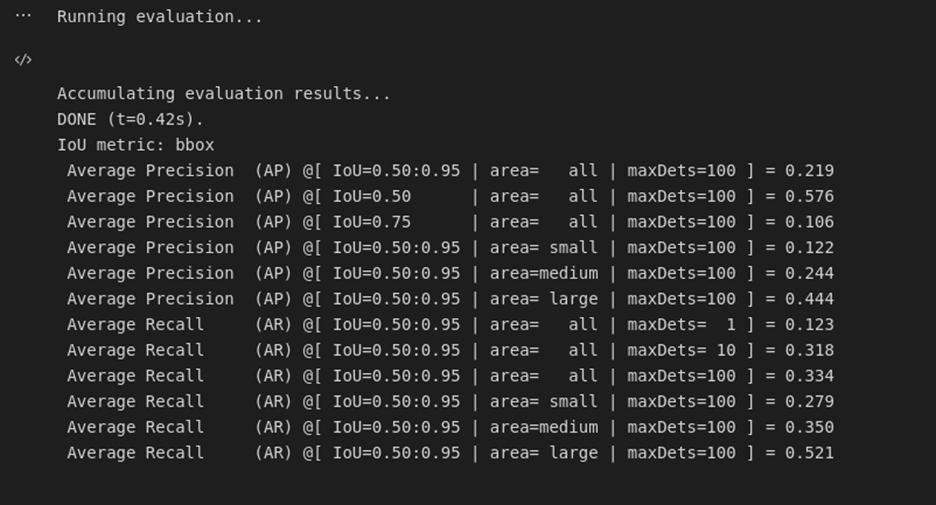
Please view my project in Github for codes, Presentation Slides, Report, Figures and Results (Click here to open: Github-Repo-link )
Please see my project report here (Click here: Final Report)
Please see my presentation slides here (Click here: Slides )
Multimodal Object Detection Transformer with Cross-Attention across Modalities
The focus of this research is to develop a transformer model that integrates the information from different modalities together to enhance the prediction as well as address the challenges posed by missing modalities.
Ideas
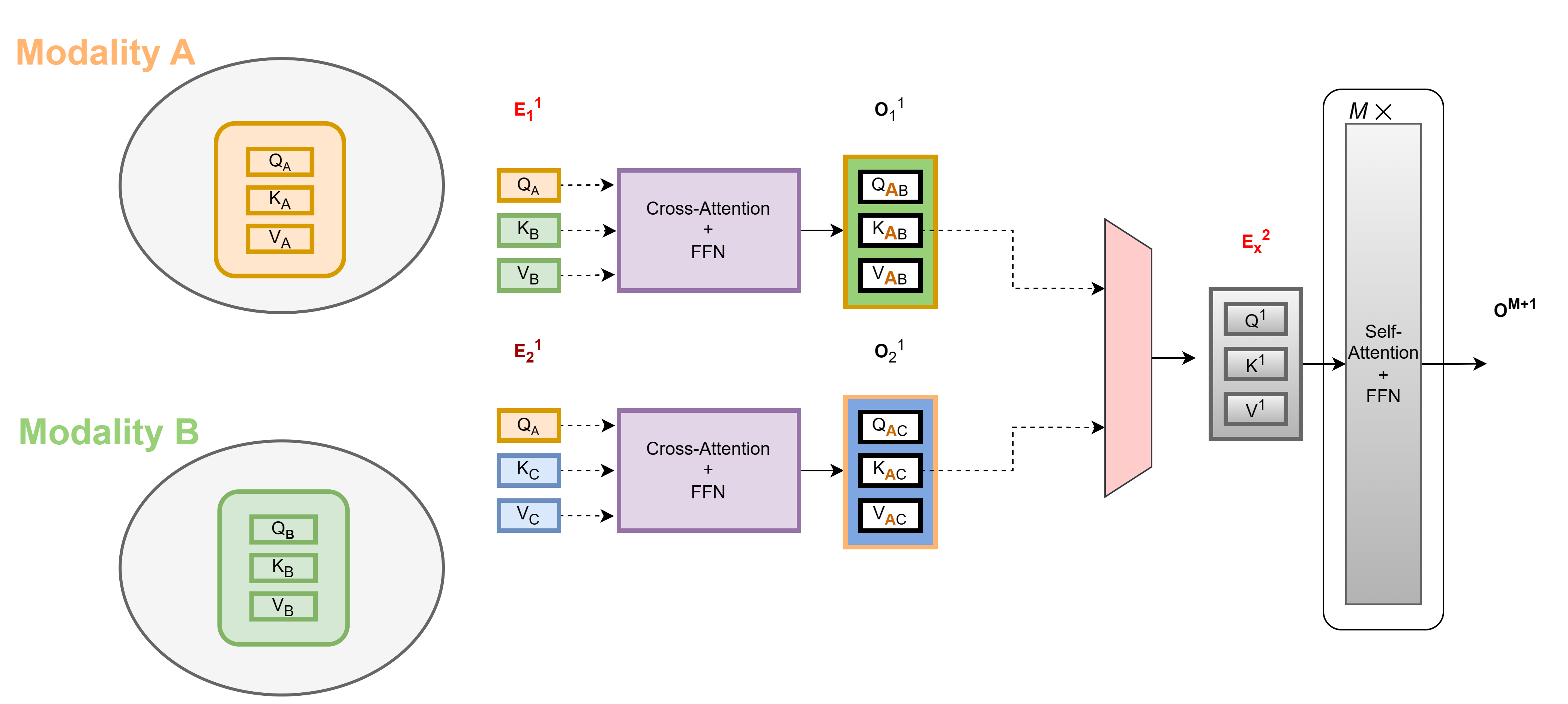
We use the concept like retrieval from database by using query, keys, and value utilizing attention calculation in transformers. We use query (a query we wish to run on a database) from one modality and keys (the keys to search on in the database) and values (values corresponding to each key in the database) from other modalities. Cross-attention in transformer encoder is used to gain context from another modality/ input type as a method of TokenFusion in channels. This is accomplished by pairwise exchange of keys and values from different modalities. For example, to gain context from text for object detection, we simply extract the queries matrix from text modality, and keys and values matrix from the RGB and IR modalities. Moreover, self-attention blocks at the end of our model architecture would allow the model to further process the combined representations as well as enable the model to understand the dependencies between different parts of the input from different modalities.
Unlike DETR, our focus in this experiment is to develop a transformer model that integrates information from different modalities together to enhance the prediction.
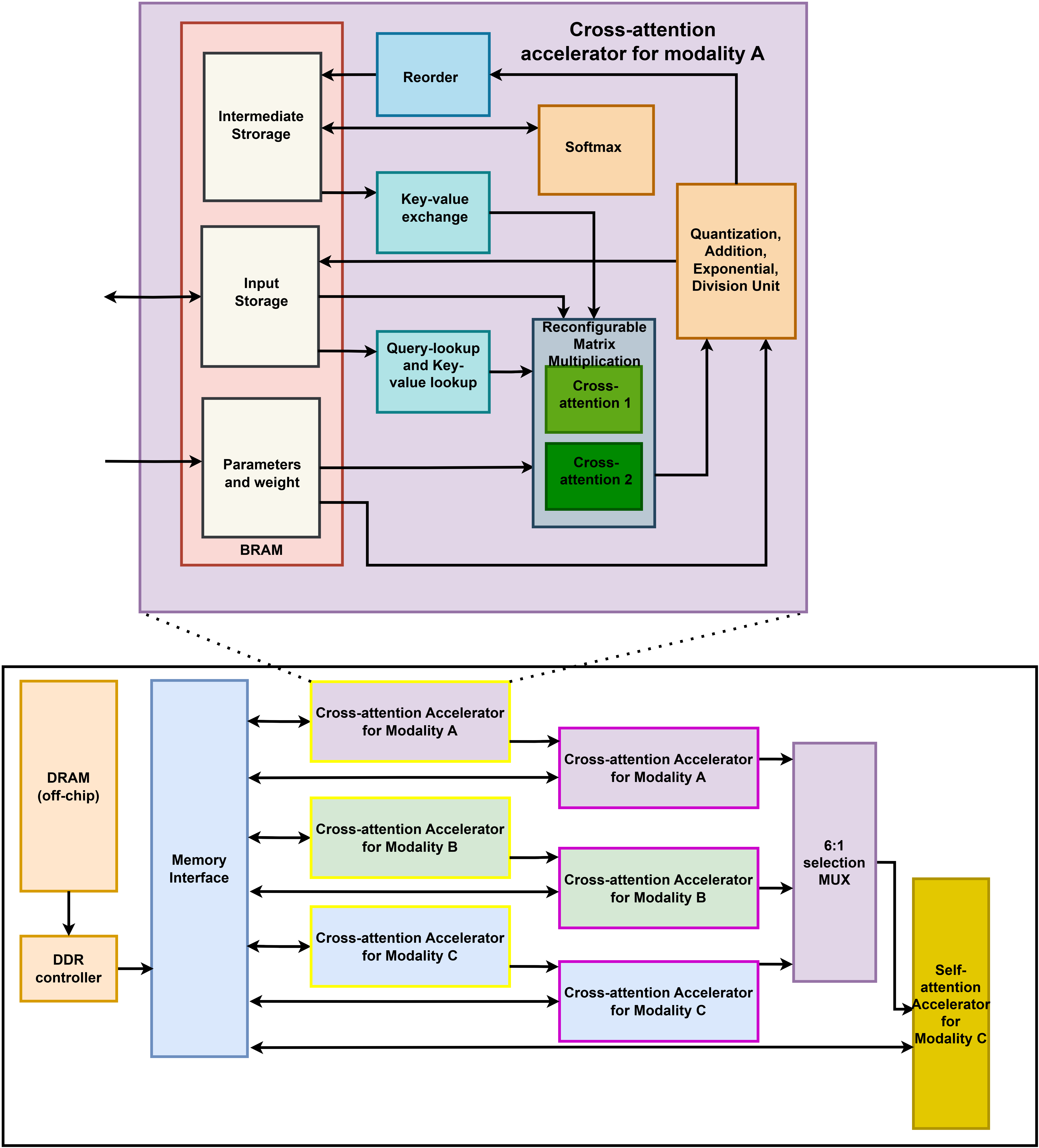
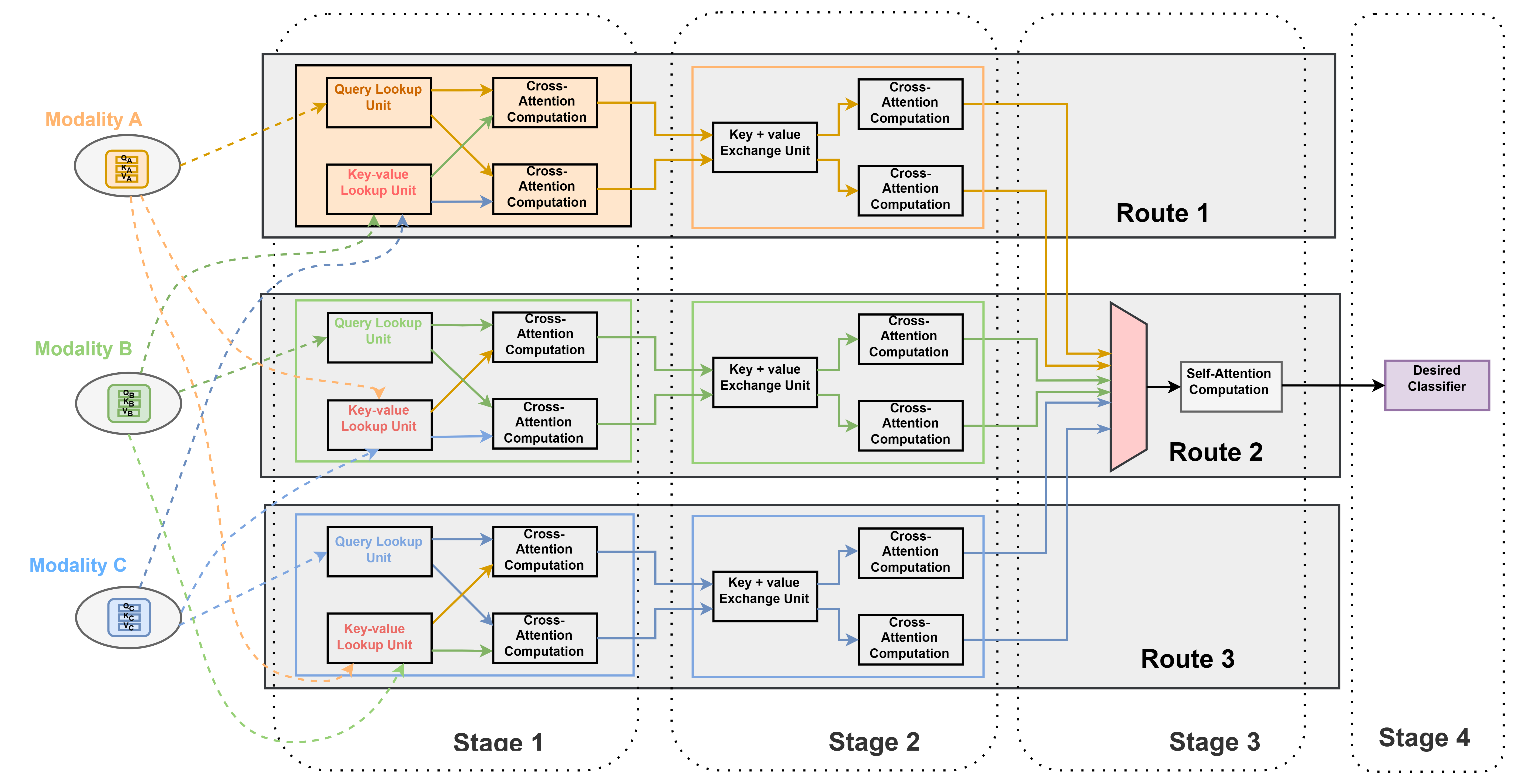
Please view my project in Github for codes. NOTE: We will update code after completion of project (Click here to open: Github-Repo-link )
RT-DETR RT-DETR (Real-Time Detection Transformer)
Using RT-DETR, an extension to Detection Transformers (DETR), as a means to conduct real-time Object Detection from video as well as webcam. RT-DETR (Real-Time Detection Transformer) represents a significant advancement in object detection technology, combining the efficiency of real-time processing with the robust capabilities of transformer architecture. As a state-of-the-art detection framework, RT-DETR optimizes the balance between computational speed and detection accuracy.
Our focus is to develop a transformer model that elevates real-time object detection through its Enhanced Hybrid Encoder and Refined Query Selection System. The encoder processes multi-scale features efficiently, while the query selection minimizes uncertainty for improved detection accuracy. The framework offers flexible speed tuning without retraining and simplifies deployment by removing dual NMS thresholds. This innovative design establishes RT-DETR as a powerful alternative to YOLO-based methods, making it suitable for diverse real-time applications requiring both speed and precision
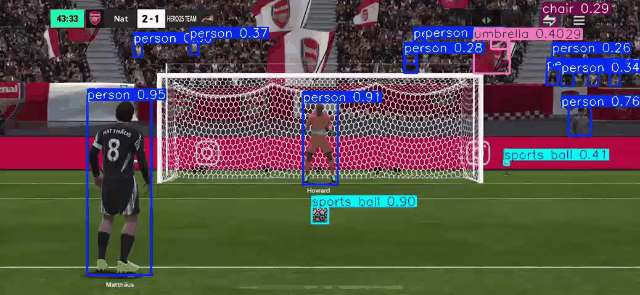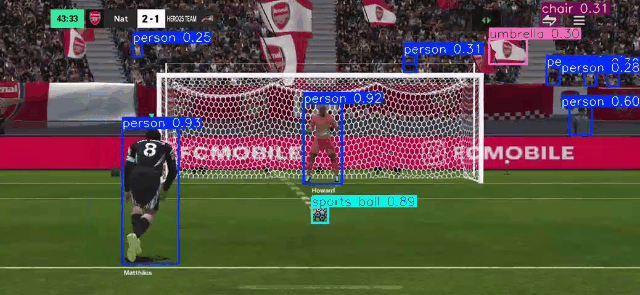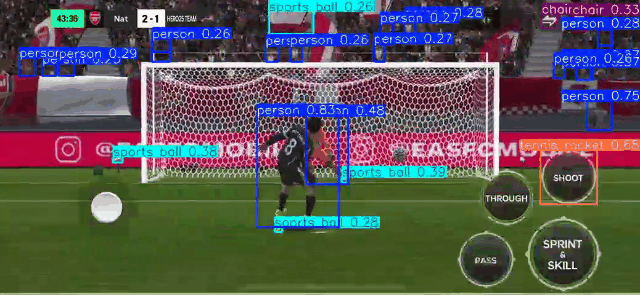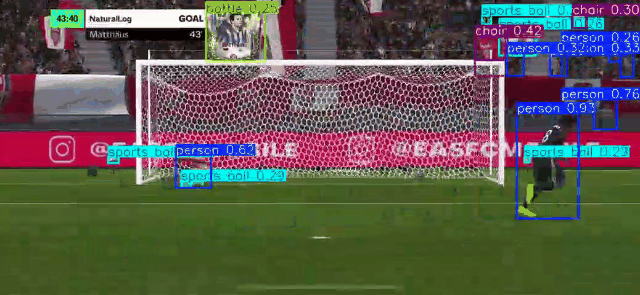
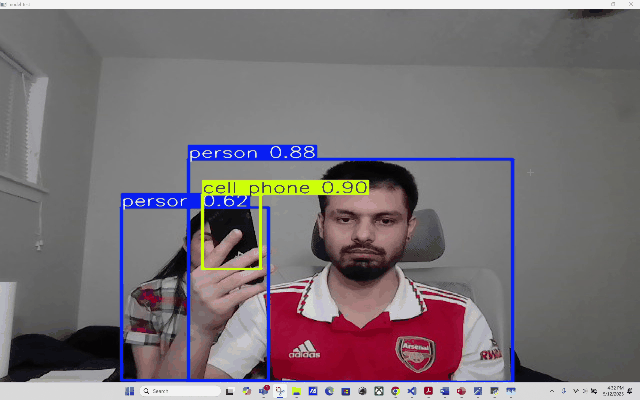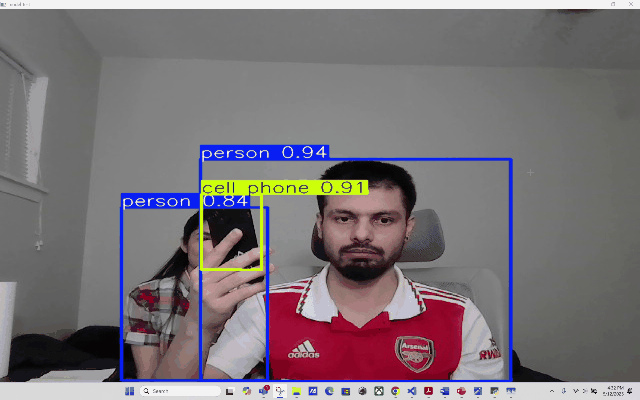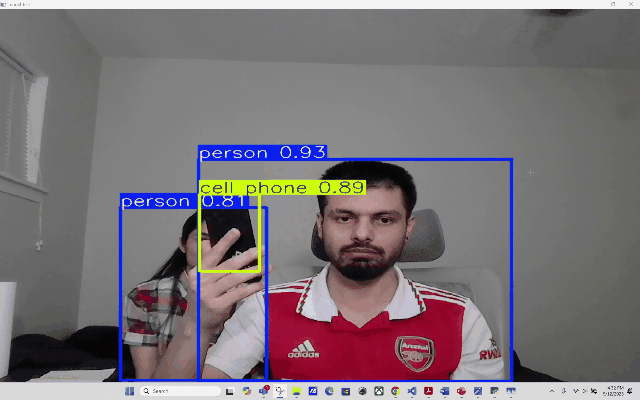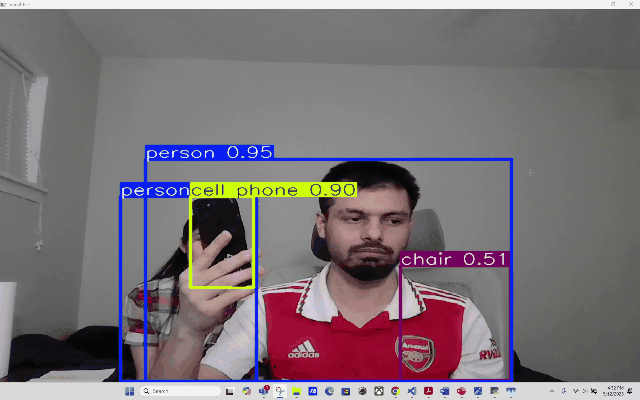
_Please view my project report in Github for codes. (Click here to open: Github-Repo-link )
Harnessing Heterogeneous Healthcare Data: An Attention Neural Network Approach
Many current machine learning (ML) models remain narrowly focused on a single data modality, which limits the ML models’ ability to make decisions from a holistic perspective. An added layer of complexity arises from the prevalent issue of data completeness. There is frequent occurence of missing modalities in healthcare data, introducing inconsistencies across patient datasets. For instance, different data modalities may be collected for different patients. Such disparities pose significant challenges for both ML and statistical analysis. To truly harness the vast potential of heterogeneous data, we develop advanced ML models that can semlessly integrate multiple data sources, addressing the challenges posed by missing modalities. We develop an attention neural network-based method for fusing heterogeneous healthcare data, emphasizing cross-modality attention transformer blocks for optimal modality integration. Moreover, we also integrate prompt learning to enhance the model’s performance with datasets that have missing modalities, preserving the core structure of the model and optimizing computational resources.
Example of two modality cross-attention in 1st stage then fusion and self-attention
Please see my AIHC.pdf Poster for more information Click here: Poster
N-Body Simulation with CPU and CUDA
The N-body problem is used in this project to mimic how particles move across space. The project comprises a Python-based serial implementation and a C++/Cuda-based parallel implementation. A program is generated that simulates gravitational force between n bodies in space, exploiting the massively parallel architecture provided by GPGPUs. This program generates N particle locations over a specified number of timesteps. Moreover, it produces gif plots to visualize the bodies in the simulation similar to stars in the galaxy. The results generated compare the performance of CPU-based implementation and GPU-based implementation.
Methodology
The force on each body in the all-pairs method is the total acceleration induced by every other particle multiplied by the mass of that body. A single thread calculates forces on a single body individually. For every particle, the total of all accelerations is evaluated to calculate the velocity and new position. Each particle’s position and velocity are updated at every time step. To parallelize the code 1024 threads were selected and for each thread aceleration, position, inverse division and softening were computed via kernels. (Run nbody.py OR nbody.cu to generate data from the N-body simulation. Run simulation.py to visualize the simulation.)
Steps to run the nbody simulation:
First, the position of N particles is generated over a given number of timesteps and stored in an output text file for both CPU and GPU implementations. The nbody.py is the python CPU-based program that creates an output py.txt text file. N and timesteps are command line arguments illustrated in the example below:
- python nbody.py 1000 150
The nbody.cu is the GPU-based program compiled to create an executable file called nbody. Executing nbody creates an output cu.txt text file. N and timesteps are command line arguments illustrated in the example below:
- ./nbody 1000 150
Next, the movement of the particle positions generated from the python and Cuda programs is plotted using a simulator program written in python. This program’s input file is supplied as a command line option for both CPU and GPU implementations illustrated in the examples below:
- python simulation.py output py.txt anim py.gif
- python simulation.py output cu.txt anim cu.gif
Note: To create gif files for the simulation we need to install imagemagick library using ! apt install imagemagick.
Finally, the runtime of both CPU and GPU implementations are plotted by increasing the number of bodies in powers of 2 via an evaluation program written in python. The number of iterations (times the number of bodies increases) is supplied as a command line input illustrated in the example below:
- python evaluate.py 7
The example in the code is running the evaluation with iterations=7.
Simulation
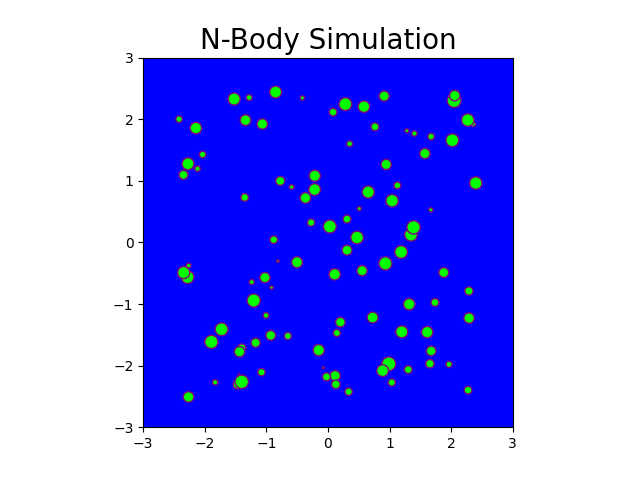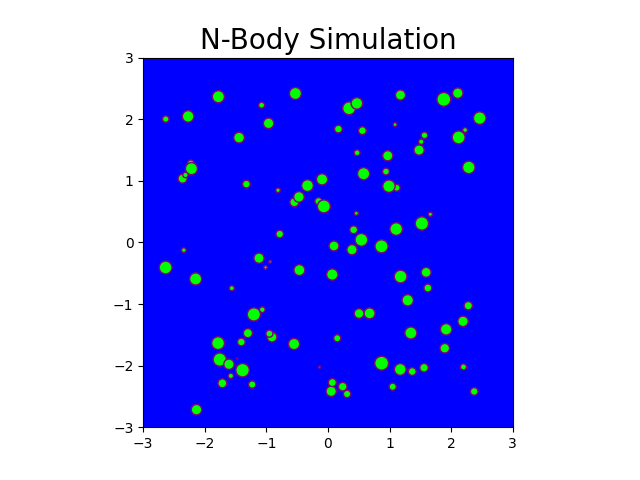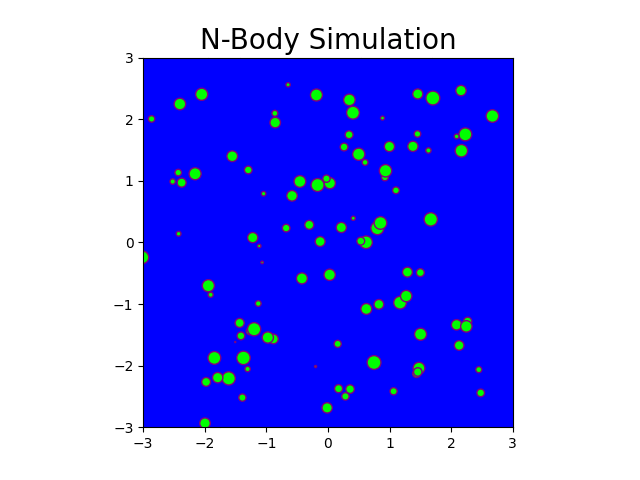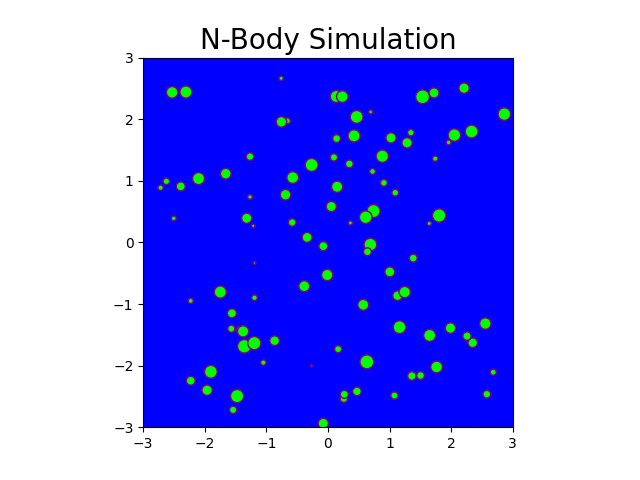 Fig: N-body simulation in CPU for N = 100 and timesteps = 150
Fig: N-body simulation in CPU for N = 100 and timesteps = 150
 Fig: N-body simulation in CUDA for N = 100 and timesteps = 150
Fig: N-body simulation in CUDA for N = 100 and timesteps = 150
Runtime Comparision Results
Runtime Comparision: The runtime were plotted for both nbody.py and nbody.cu files by varying the number of bodies in power of 2 and selecting the timestep as 150
Figure below shows the runtime for N=10 (1024 bodies). We can observe that the paralleled GPU implementation required approximately 30 seconds and serialized CPU implementation required approximately 3000 seconds (50 minutes approx).
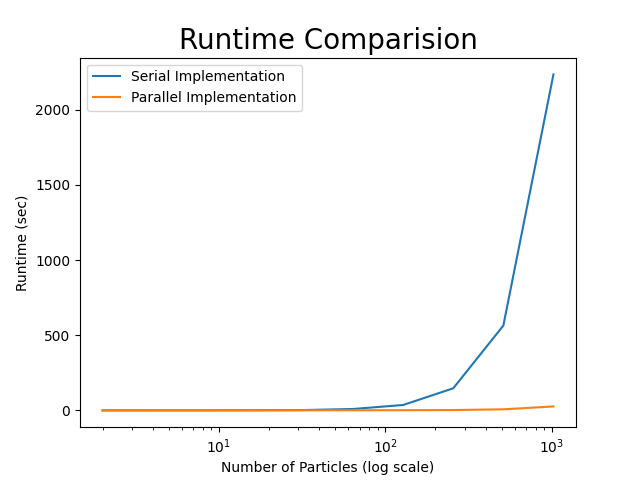
CUDA provides an outstanding hardware layer for running massively parallel programs, and CUDA-enabled GPUs shine when pushed to their limits (upwards of 10000 threads per GPU). It is also dependent on utilizing the computing specifications. The location of the n bodies can be simulated over a specified number of timesteps using python CPU-based and CUDA GPU-based implementation. The performance of GPUbased implementation in GPU is approximately 99.6 times better than CPU-based implementation for my program.
Please view my project in Github for codes, Report, Figures and Results (Click here to open: Github-Repo-link )
Please see my project report here (Click here: N Body Report)
Link to directly run the project in google colab: (Click here: Gooble Colab link)
NOTE: see Steps to run the nbody simulation from README file in github or follow instructions in the report
Performance Impact of Basic Cache Configuration Parameters Using SimpleScalar
This paper investigates the performance impact of several basic cache configuration parameters, such as the L1, L2, and TLB cache size, associativity, and block size using the SimpleScalar ”sim-outorder” model and the SPEC 2000 benchmark suite. The results generated illustrate the relationship between Miss Rate and modifications in cache size, associativity, and block size. The results also reveal the impact of the multilevel cache design as well as the efficacy of the TLB cache in enhancing data locality.
Experimental Results
The cache parameters corresponding to the Instruction cache and data cache in the configuration files were varied to form 10 different setups. Then, a shell script was used to run each configuration on each SPEC2000 benchmarks. First, 100 million instructions were skipped to ensure proper warming up of the caches. Then, each benchmark was run for 100 million instructions to acquire the results.
The results illustrate the relationship between Miss Rate and modifications in cache size, associativity, and block size. The results also reveal the impact of the multilevel cache design as well as the efficacy of the TLB cache in enhancing data locality.
Images
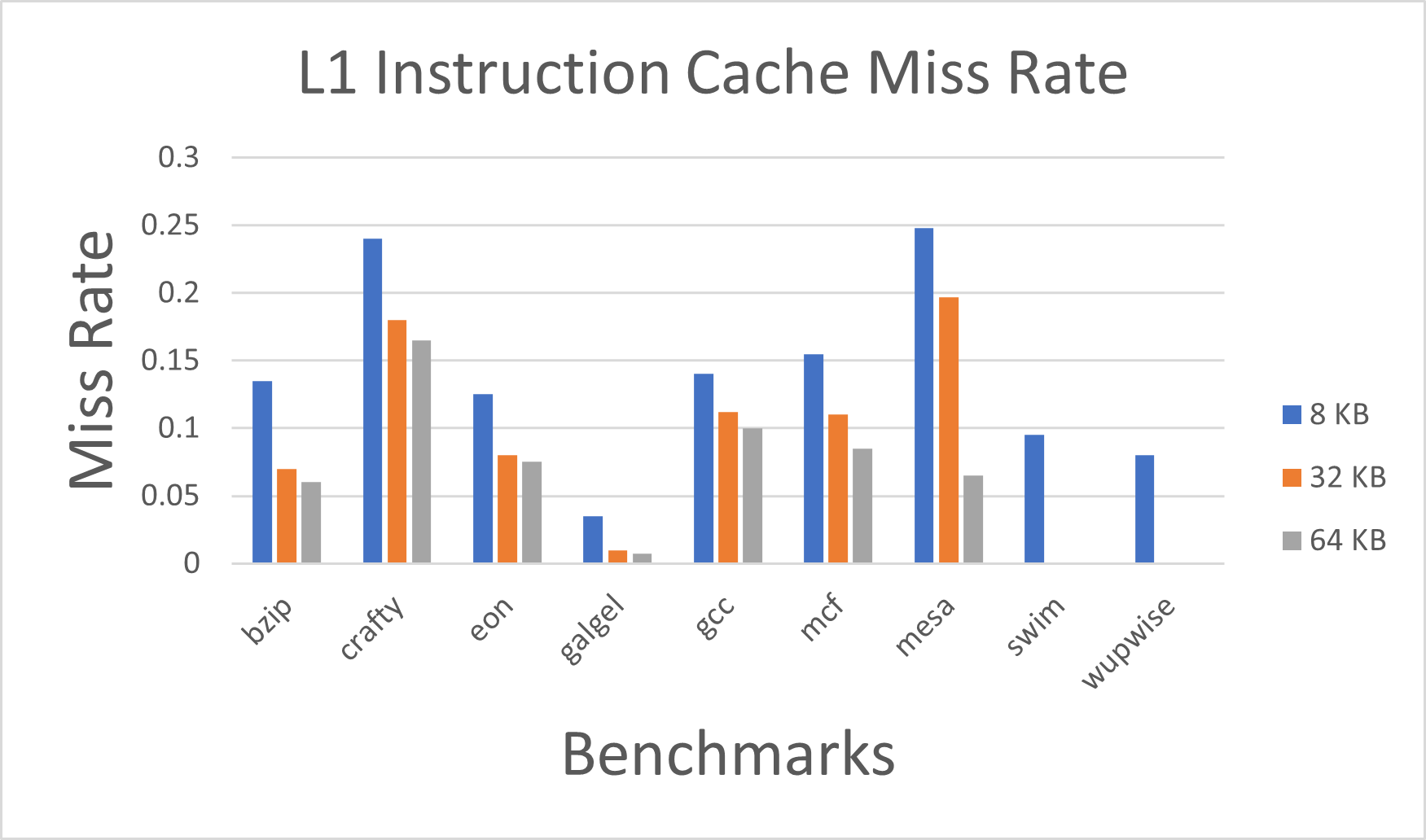 Fig. 1. Instruction Cache L1 Miss Rate by changing the cache size with constant block size of 32B and 1-way associativity.
Fig. 1. Instruction Cache L1 Miss Rate by changing the cache size with constant block size of 32B and 1-way associativity.
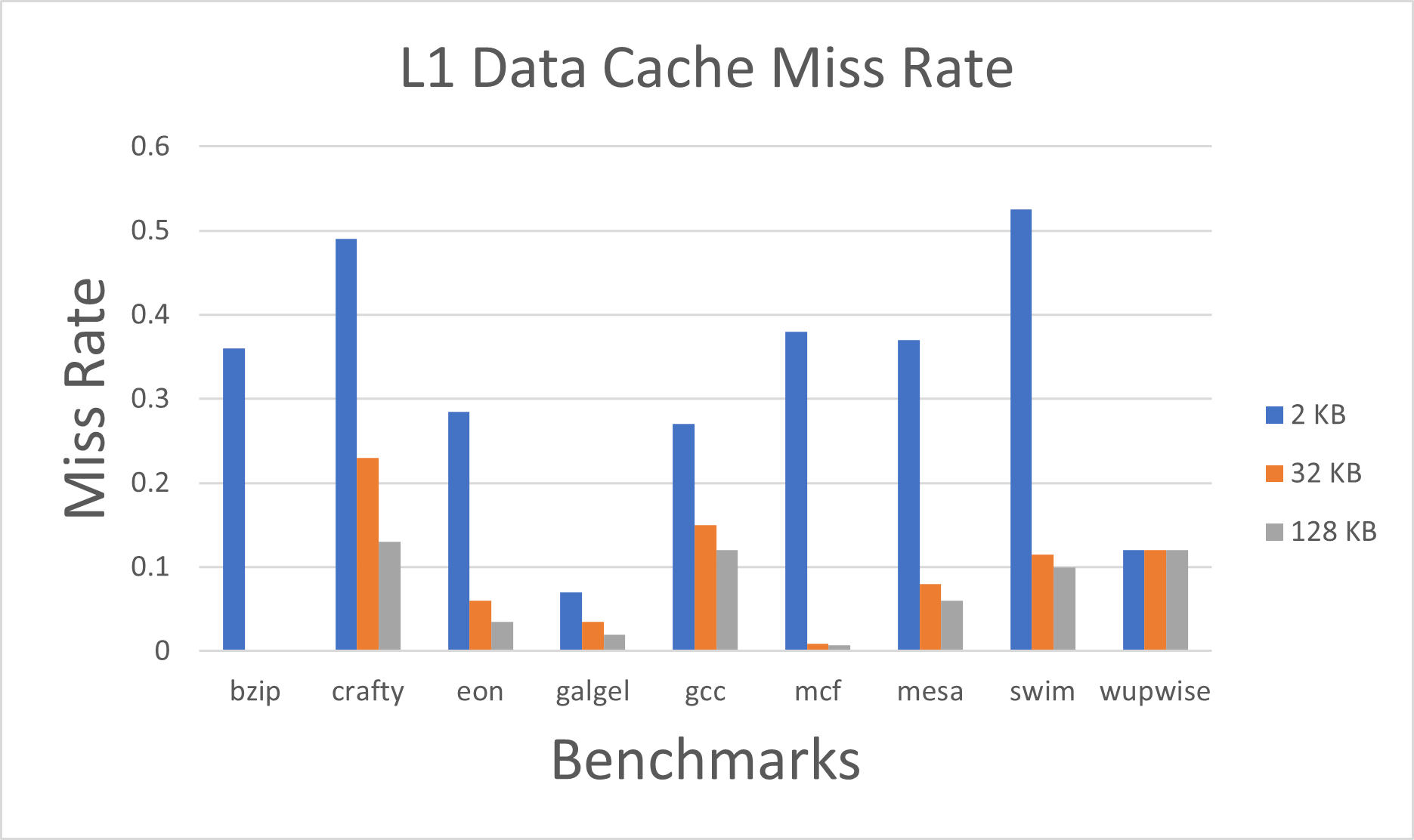 Fig. 2. Data Cache L1 Miss Rate by changing the cache size with constant block size of 32B and 1-way associativity.
Fig. 2. Data Cache L1 Miss Rate by changing the cache size with constant block size of 32B and 1-way associativity.
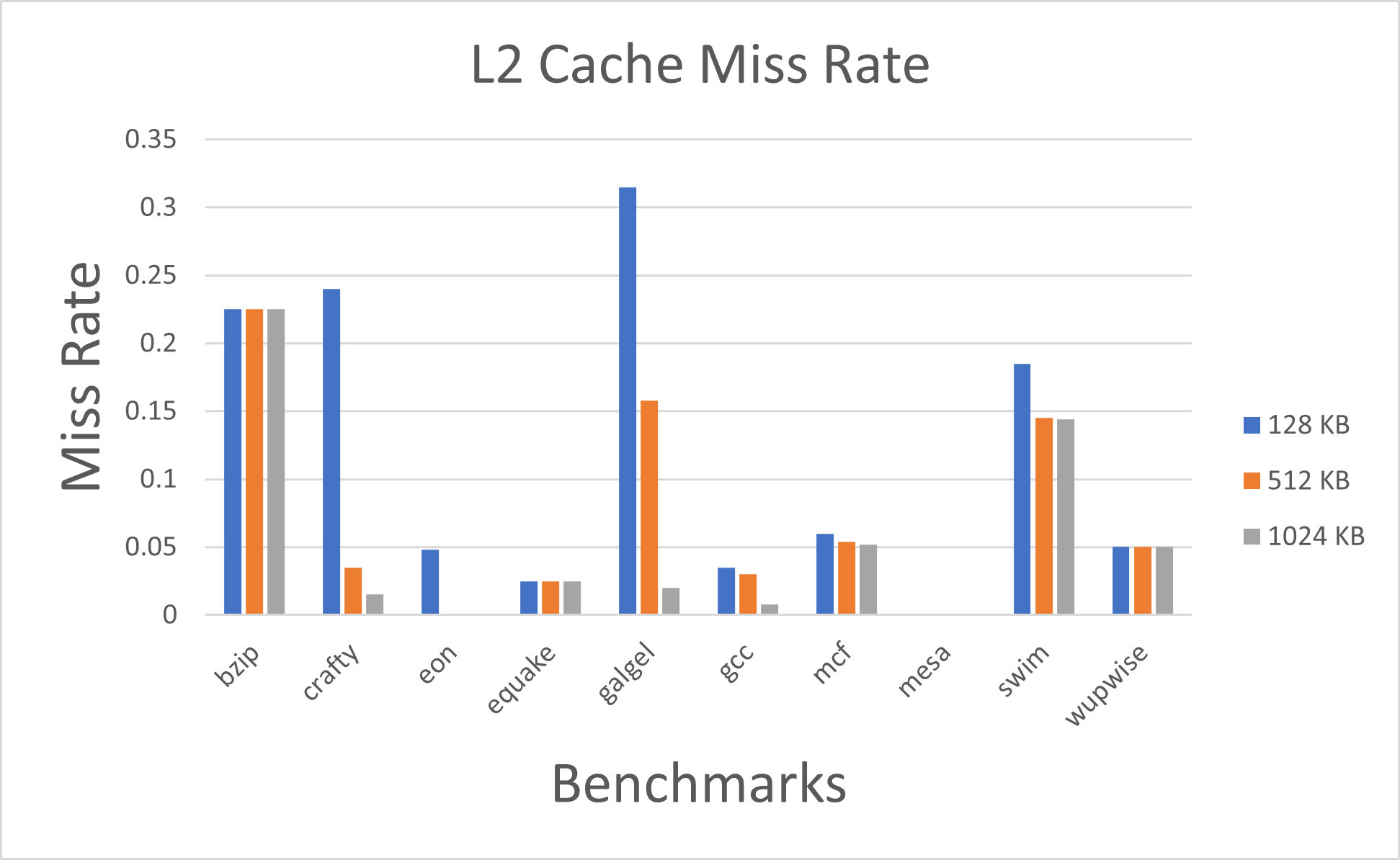 Fig. 3. Miss Rate for L2 cache by changing the cache size with constant block size of 64B and 4-way associativity
Fig. 3. Miss Rate for L2 cache by changing the cache size with constant block size of 64B and 4-way associativity
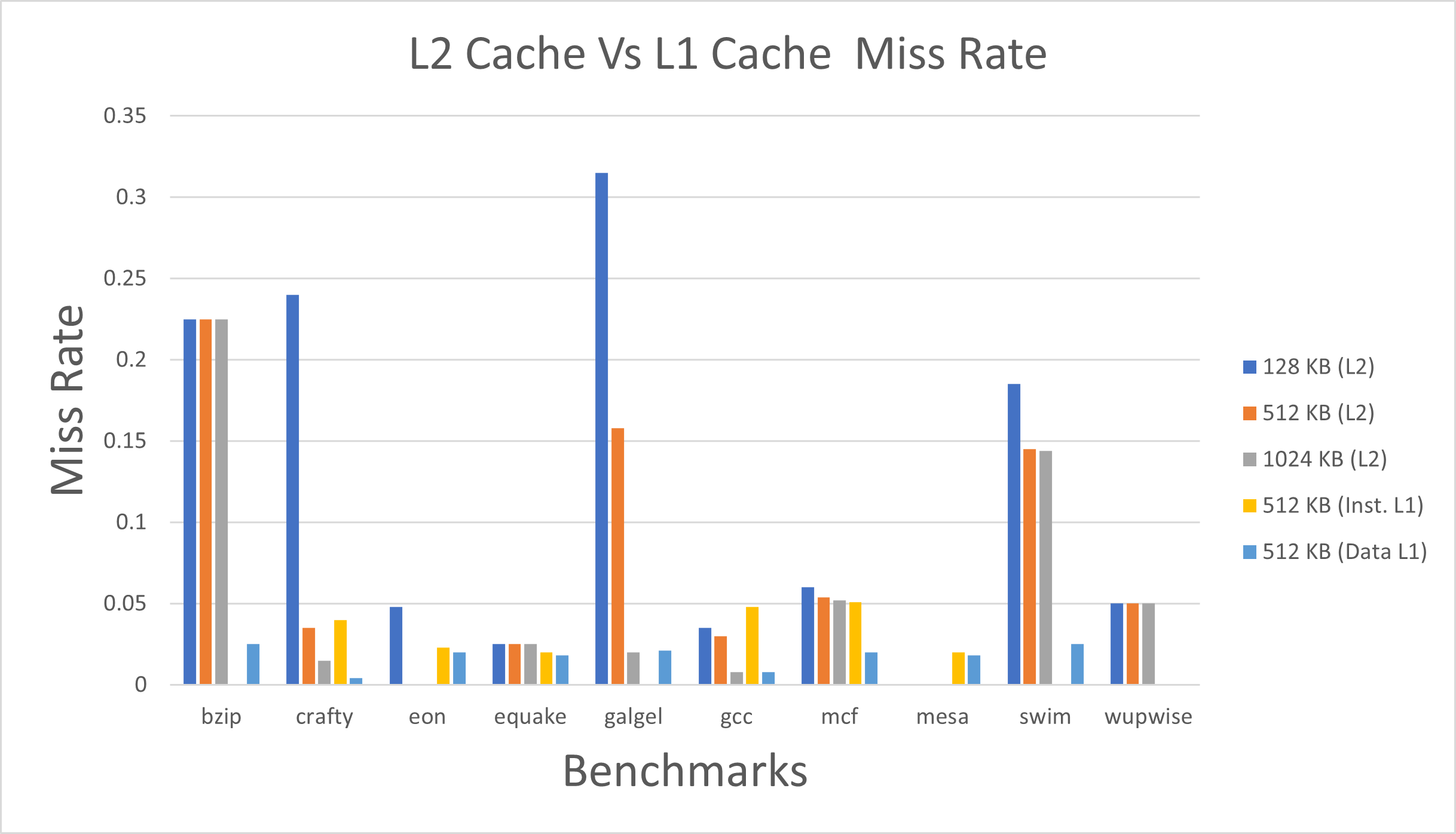 Fig. 4. L2 Cache Vs L1 Cache Miss Rate by changing the L2 cache size and keeping block size of 64B and 4-way associativity (L1 cache size is 512 KB).
Fig. 4. L2 Cache Vs L1 Cache Miss Rate by changing the L2 cache size and keeping block size of 64B and 4-way associativity (L1 cache size is 512 KB).
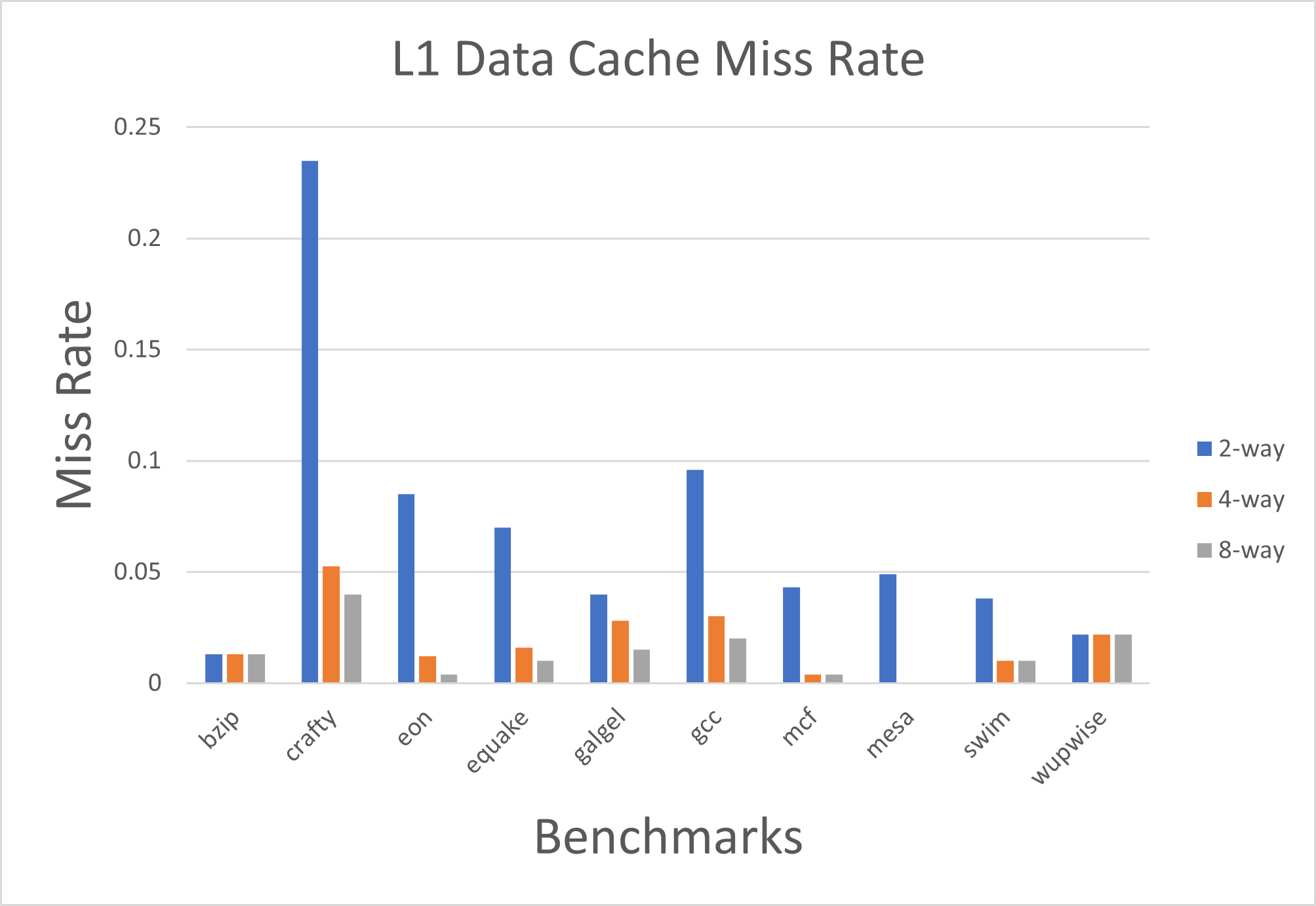 Fig. 5. Miss Rate for L1 data cache by changing the associativity with constant cache size of 32KB and block size of 32B.
Fig. 5. Miss Rate for L1 data cache by changing the associativity with constant cache size of 32KB and block size of 32B.
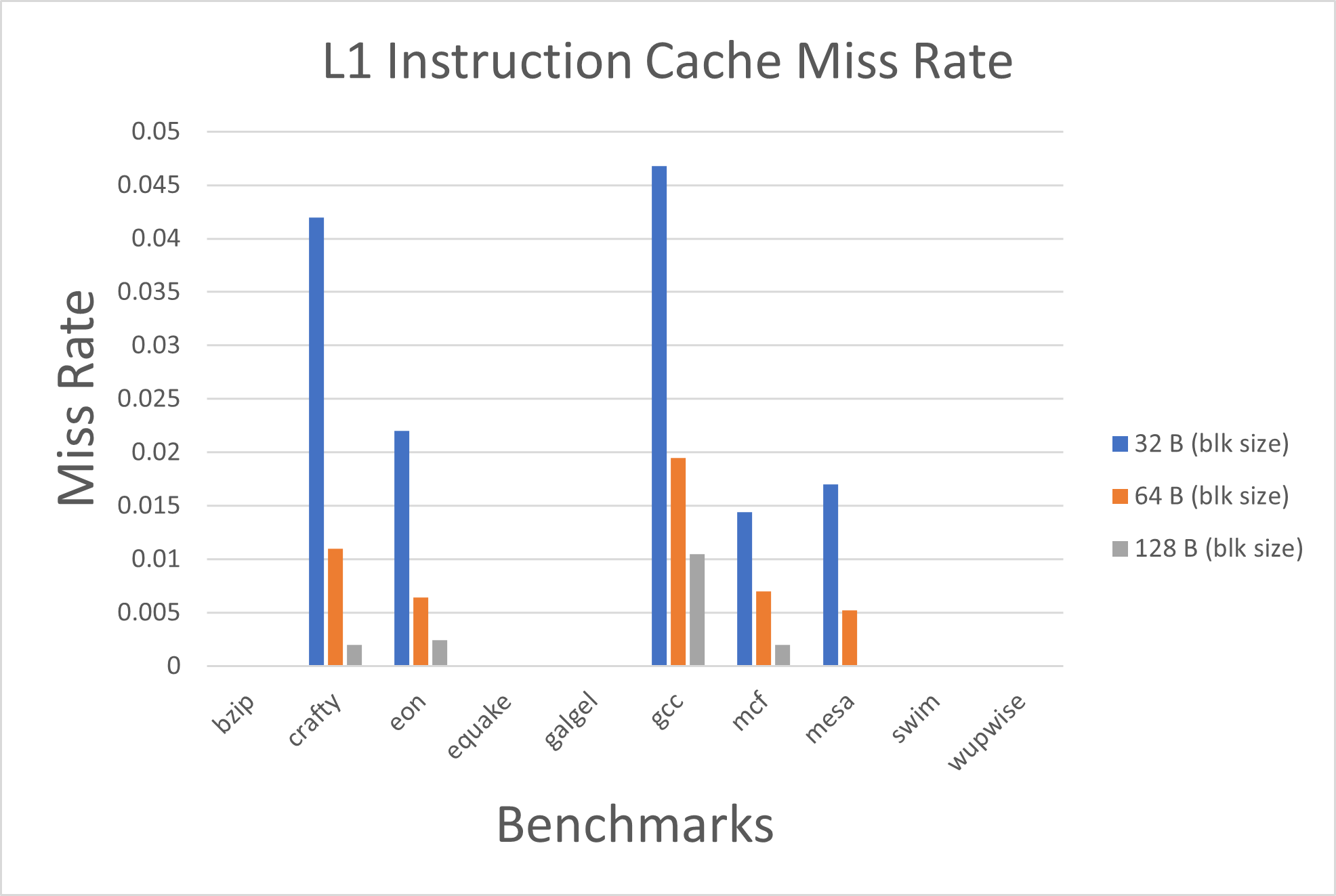 Fig. 6. Miss Rate for L1 Instruction Cache with change in block size setting constant cache size of 512KB and associativity as 1-way.
Fig. 6. Miss Rate for L1 Instruction Cache with change in block size setting constant cache size of 512KB and associativity as 1-way.
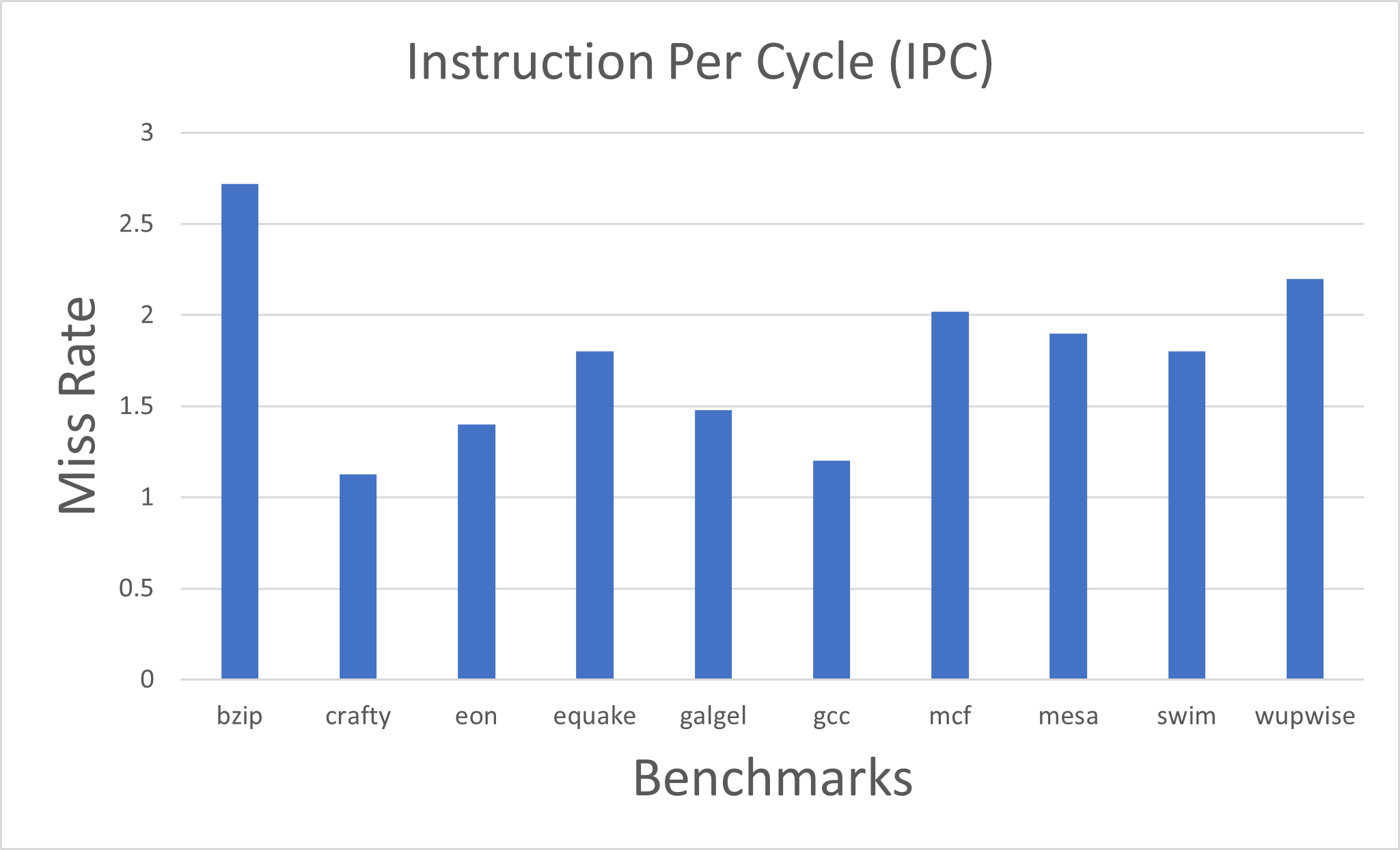 Fig. 7. IPC value for every Benchmarks
Fig. 7. IPC value for every Benchmarks
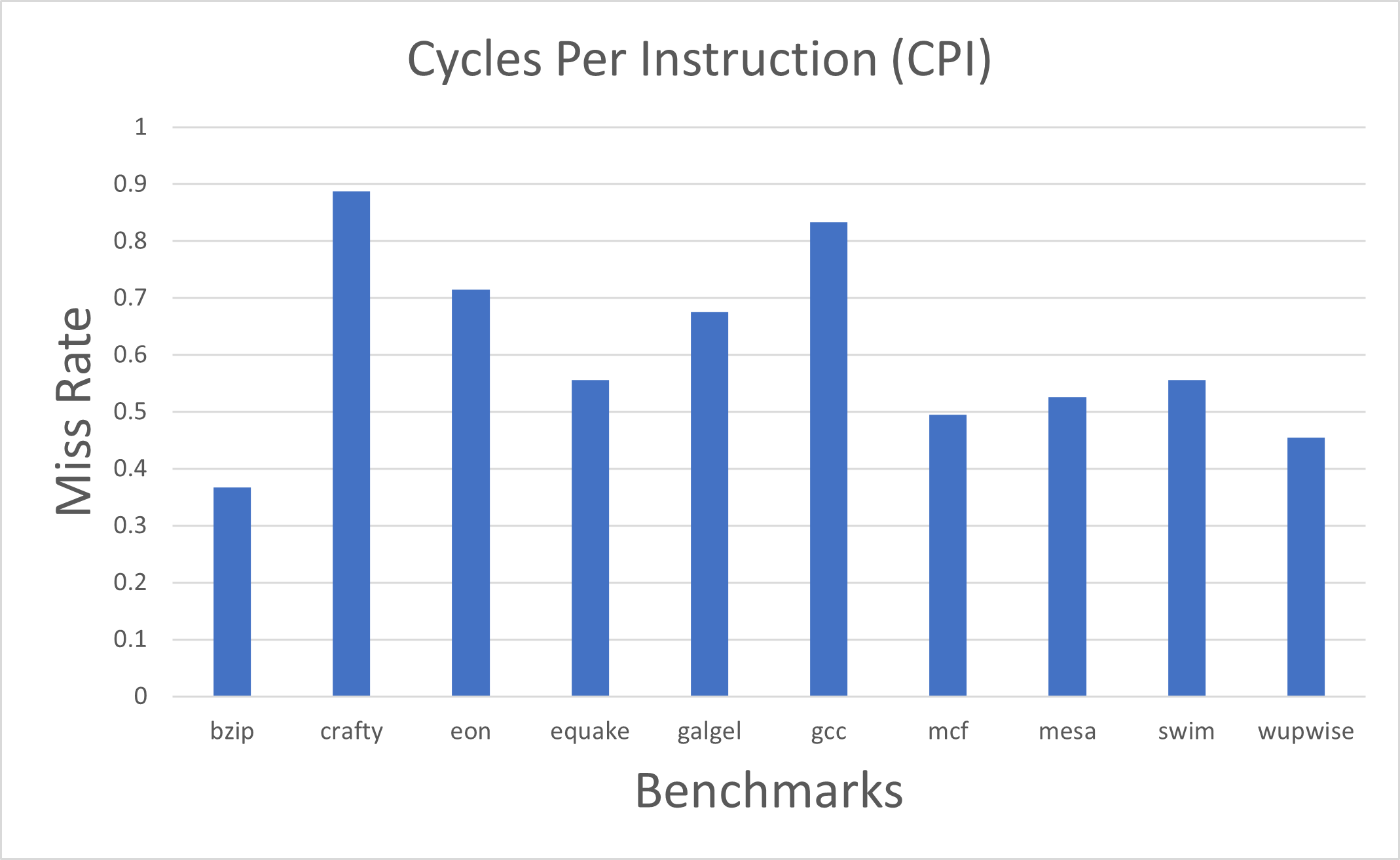 Fig. 8. CPI value for every Benchmarks
Fig. 8. CPI value for every Benchmarks
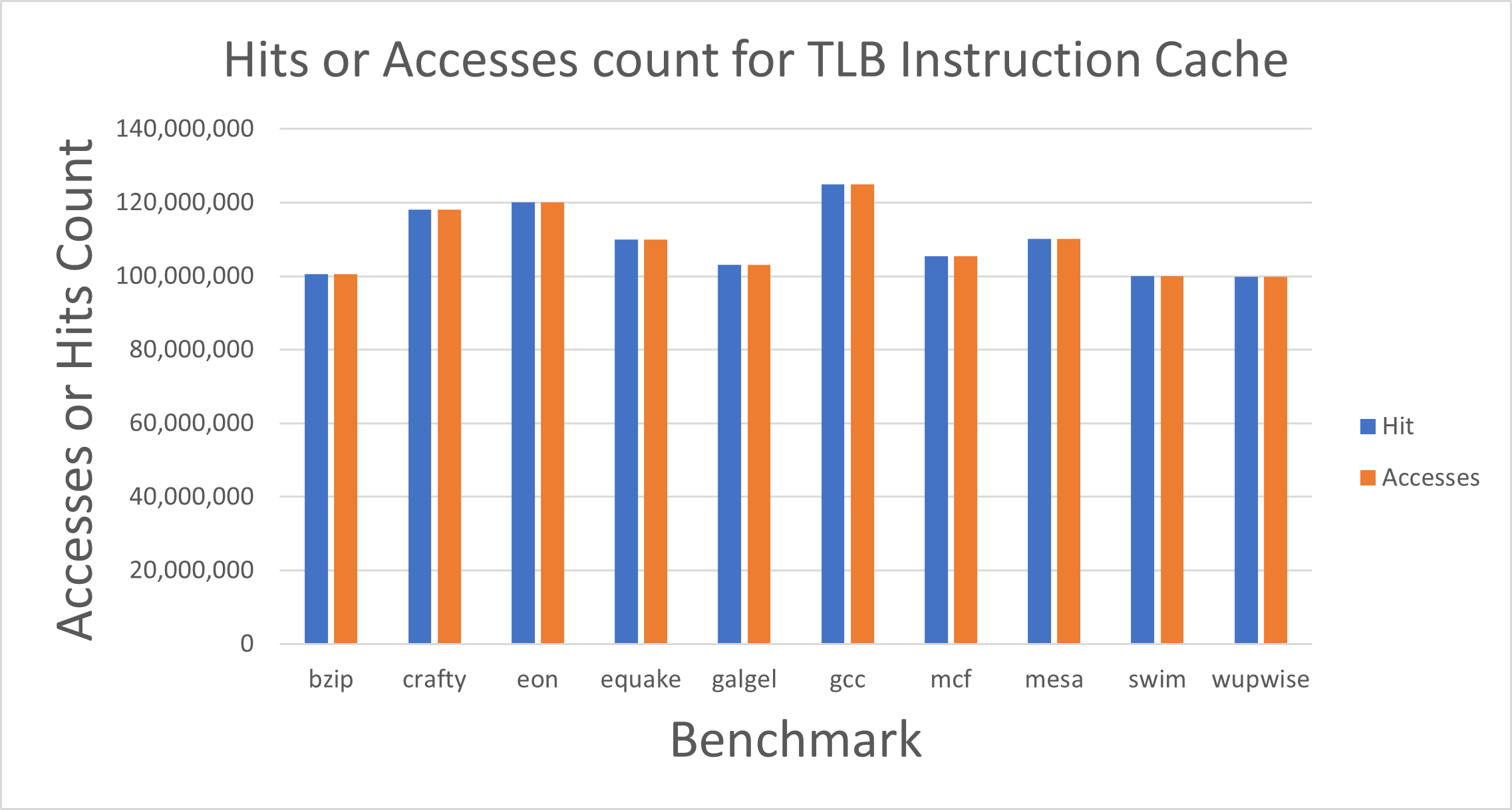 Fig. 9. Hit Count and Accesses for TLB Instruction Cache
Fig. 9. Hit Count and Accesses for TLB Instruction Cache
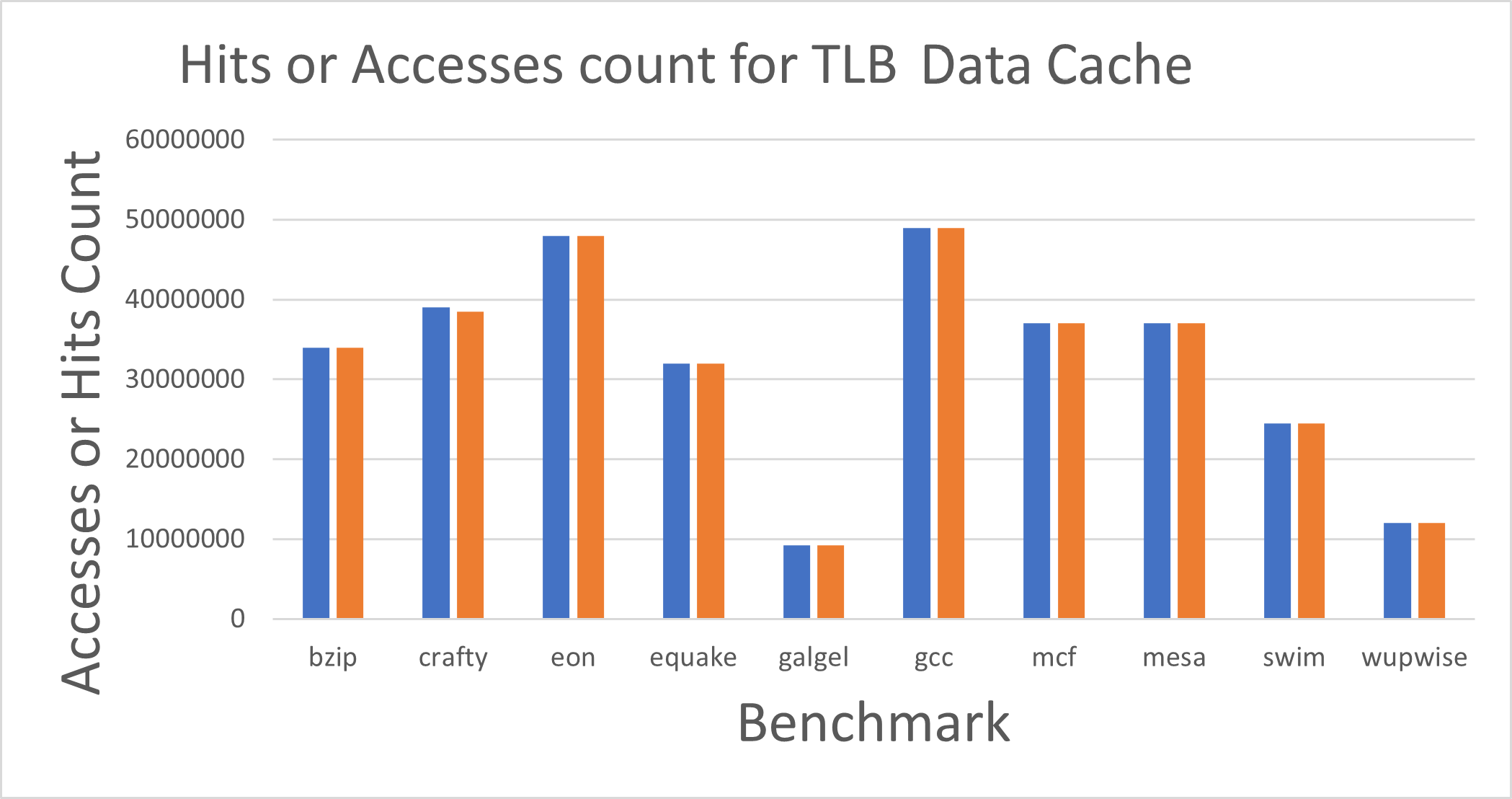 Fig. 10. Hit Count and Accesses for TLB Data Cache
Fig. 10. Hit Count and Accesses for TLB Data Cache
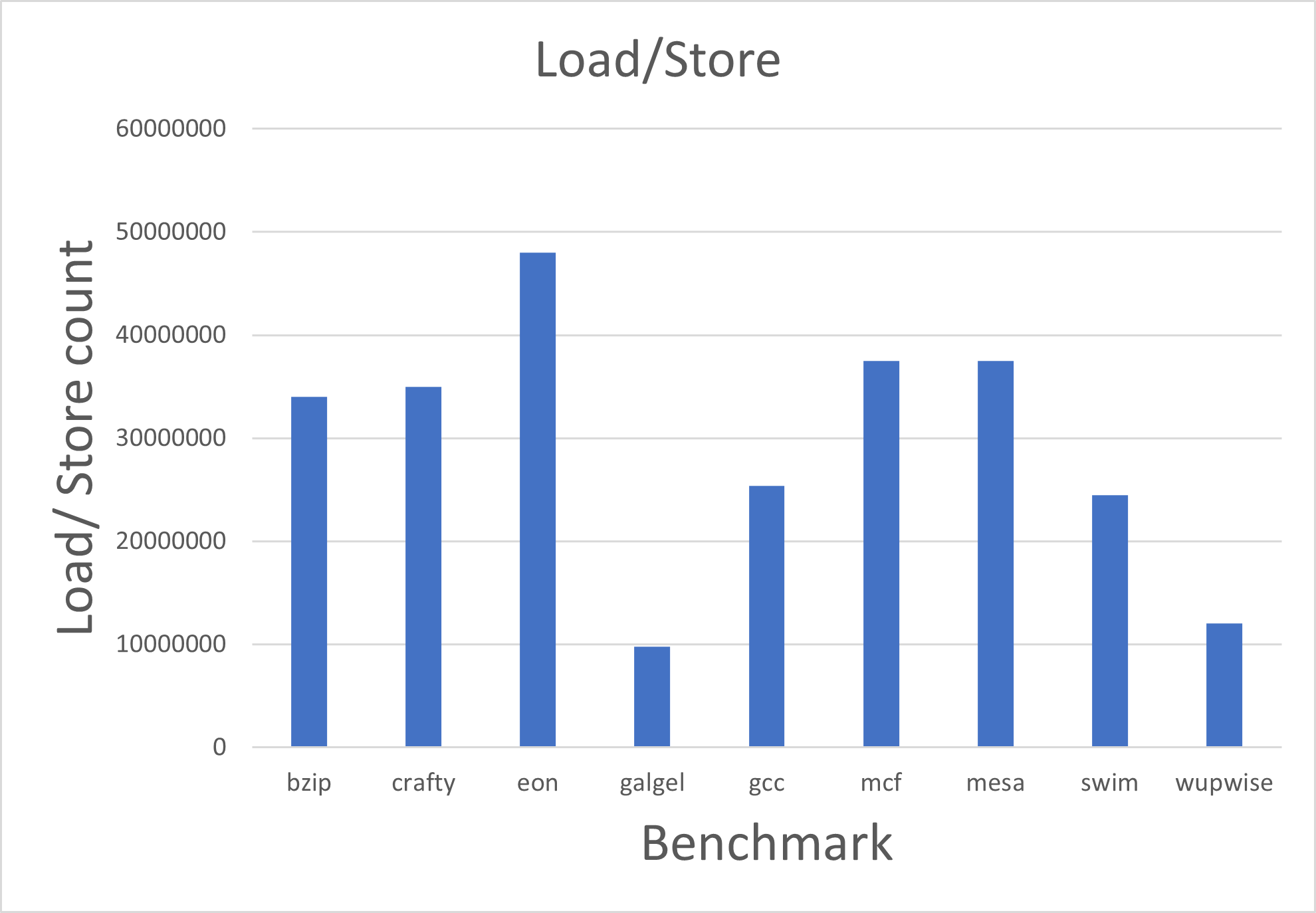 Fig. 11. Load/ Store Count in benchmarks.
Fig. 11. Load/ Store Count in benchmarks.
Please view my project in Github for codes, Report, Figures and Results (Click here to open: Github-Repo-link )
Please see my project report here (Click here: ACA Report)
Android-App-Remote-Controlled-Vehicular-Robotic-Arm
Remote controlled system (robot) from self developed android app that constantly performs the task of picking an object and moving it to the desired location (both automatic and manual).
In this project, a vehicular robotic arm is made and controlled by an Android mobile app. The development of this model is through ESP32 along with a mobile phone for controlling the robot. This prototype may be expected to overcome the problems of picking hazardous objects or non-hazardous objects that are far away from the user and where displacement of very heavy objects is needed from one place to another as automation is required in many industries.
Images

Bluetooth App Developed
Project DEMO video:
This is the DEMO video link for our project: (Click here: Video)
Multi-threaded Ray Tracing
This project implements ray-tracing algorithm that performs direct illumination of spheres. Here, the C++ codes will take two text files as input, describing a (a) list of spheres and a (b) list of lights. Then, it will output the ray-traced image as a Targa file which is further converted into JPG format using python code. One of the major objective of the project is to decrease the latency via parallelism. I successfully parallelized the codes using the C++ std::thread library.
Output
 Fig. 1. Ray Tracing and illumination of Spheres
Fig. 1. Ray Tracing and illumination of Spheres
Please view my project in Github for codes, and figures (Click here to open: Github-Repo-link )